
How Enterprise Architecture strengthens Agile development

SAFe, scrum, domain-driven design, Spotify… Agile project frameworks & methodologies have made their way into the enterprise, especially IT software project management.
In this dynamic environment, a company should not lose sight of its enterprise architecture, which is essential to understanding how business transformation initiatives can succeed.
Let’s explore how and why companies must ensure their enterprise architecture discipline can fuel SAFe and Agile productivity when applying the right methods.
Enterprise Architecture is an enabler for Agile
Enterprise architecture (EA) designs, plans, and manages enterprise-level structures and systems. It helps organizations achieve their desired outcomes by aligning their strategies, processes, and technologies.
Enterprise architecture (EA) must adapt and evolve to support a company’s ecosystem and become enablers. It enables an organization to scale its business transformation goals as required. Scaling down is especially important to helping Agile delivery teams quickly understand where the enterprise needs to adapt as the market evolves.
How does Enterprise Architecture work with Agile?
EA has been increasingly used to support agile development processes in recent years. Agile development relies on several architectural decisions that must be made early in the project. For example, decisions about technology platforms, application integration, and data management must be made before development begins.
EA provides a framework for making these decisions systematically and consistently. This ensures that the resulting architecture is aligned with the organization's strategy and can effectively support the agile process. In addition, EA can help identify potential risks and issues early on, saving time and money in the long run.
In Figure 1 below, you can see this concept in action. It shows how enterprise architecture can interpret the enterprise's vision and goals into a roadmap and strategy.
Then, it can be scaled as needed and embedded into Agile sprints. This ability to change and adapt creates the flexibility necessary to fuel Agile and ensure a successful and aligned output.
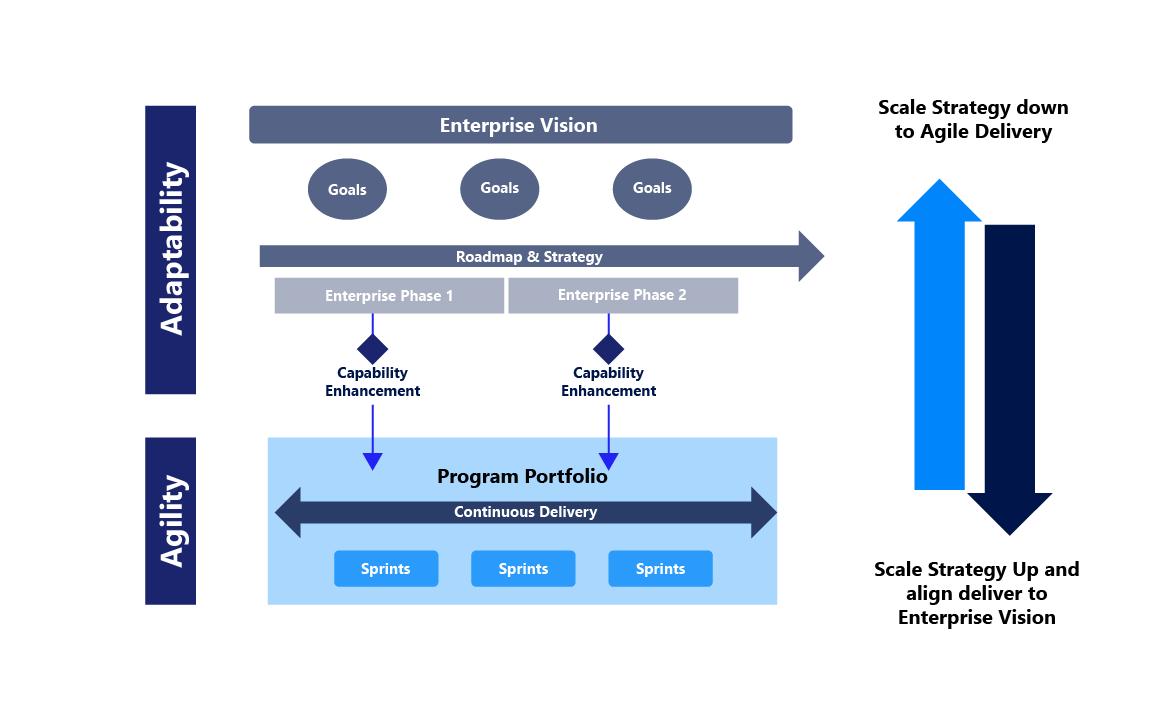
Figure 1: Enterprise architecture and Agile-at-scale
An Agile mindset provides many benefits to companies. However, it also has some downfalls. This becomes evident when Agile’s suggested improvements may not align with overall business goals. Agile methods are activity-focused because they focus on executing a project.
Companies must ensure that programs are executed to help the business achieve sustainable growth. Aligning these results to the company's strategy is crucial, and this is where the enterprise architecture discipline shines.
How Enterprise Architecture strengthens Agile development
Agile Enterprise Architecture Principles
Several agile enterprise architecture principles can help organizations become more agile and responsive to change. These include:
- Creating a lean and modular architecture involves creating a simpler and more streamlined architecture that is easy to change and adapt as needed.
- Developing in short cycles: This helps ensure that changes can be quickly implemented and tested and that feedback is continuously incorporated into the development process.
- Automating key processes: This helps free up resources to be focused on more strategic tasks.
- Encouraging collaboration: This ensures that all stakeholders are involved in the development process and that ideas can be quickly shared and implemented.
- Focusing on business value means prioritizing features and functionality that will impact the business more than simply nice ones.
Enterprise architecture is about aligning Agile outputs to strategy.
Enterprise architecture is all about aligning the outputs of an Agile software development process with an organization's overall strategy. This means creating a blueprint for how the software will support business goals and objectives.
The enterprise architect ensures the software development team understands the big picture and how their work fits it.
This can be challenging, but the new and modern enterprise architect needs to be business outcome-driven. Simply put, the primary outcome he/she needs to look for is aligning the business architecture (objectives, regulations, capability planning, strategy, value stream mapping) to the IT architecture and portfolios.
Understanding how the company's architecture works today and whether it will support the business objectives is key, especially for Agile developments to be successful.
An enterprise architect plays a crucial role in aligning the enterprise roadmap(s) to the IT roadmap(s) by answering a crucial question:
Will we adapt quickly enough to meet our market in time?
The key to reconciling Agile design
The key to reconciling Agile design is understanding the differences between the two approaches. Agile focuses on iterative development, meaning requirements constantly evolve and change. On the other hand, design is a more linear process, focusing on creating a detailed plan upfront.
One way to reconcile these two approaches is to start with a high-level design that outlines the overall architecture and framework.
This can be done using Agile techniques such as user stories and storyboards. Once the high-level design is complete, you can flesh out the details using a more traditional approach.
Another way to reconcile Agile and design is to use a hybrid approach that combines elements of both.
For example, you could start with a detailed design for the core functionality and then use an Agile approach for the remaining features. This allows you to get the best of both worlds – a well-designed core with the flexibility to adapt to changing requirements quickly.
Agile Development projects create emergent designs, and architects designing “to be” architecture cannot keep up. In that spirit, the concept of intentional architecture becomes key.
Intentional architecture represents the intent or the plan the organization wants to achieve.
It includes documenting business goals, value streams, capabilities, applications, new technologies, data, and APIs for each phase of the company's roadmap. An enterprise architect can do this in two steps:
- The first objective of an enterprise architect should be to align the business objectives to the intentional architecture. Of course, even the best-laid plans change as an organization adapts to changing market conditions, so an enterprise architect needs to be mindful of how the guardrails must be adjusted.
- The second objective of an enterprise architect is to reconcile the intentional architecture to the new designs created by the Agile Development teams. In this context, the EA team's reaction often engages “force” to make the Agile Development team and operation follow their vision. However, this is the exact opposite of what EA can and should do. Rather, the EA team should focus on reconciling the agile development to the intentional architecture and understand the impact on the strategy, if any.
In this scenario, enterprise architects play a crucial role in ensuring the ability to scale the strategy down to Agile Delivery and deliver the enterprise vision.
Today’s enterprise architect can focus on business outcomes, enabling the enterprise to marry business adaptability to project agility.
Figure 2 below shows how this comes to life in a walk, jog, run analogy.
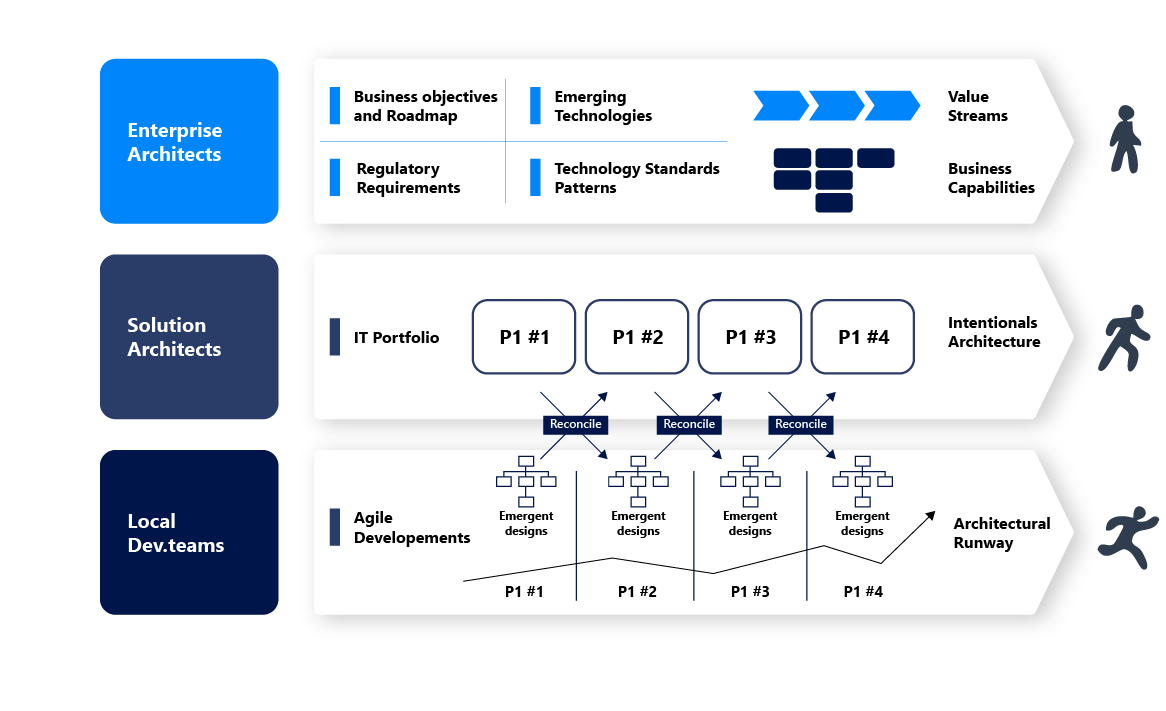
Figure 2: Agile Support Developments with intentional architecture at different paces
Regardless of your chosen approach, communication and collaboration are essential for success. Ensure all stakeholders are involved from the beginning and that each team's responsibility is clearly understood.
What are some of the key benefits of enterprise agile?
Enterprise agile has many benefits, but some key ones are improved communication, better-quality products, and faster delivery times.
Enterprise agile helps improve communication by breaking down barriers between departments and allowing for more collaboration. This improved communication leads to better quality products because everyone is on the same page and working together towards a common goal. Enterprise agile also results in faster delivery times because there is less red tape and more flexibility to make changes quickly.
Overall, enterprise agile leads to better communication, higher quality products, and faster delivery times – all of which benefit businesses.
Agile Methodology and Enterprise Architecture crucial for Business Success
Agile methodology can coexist with enterprise architecture and complement each other very well. Enterprise architecture provides the framework and foundation for an organization, while agile methods offer flexibility and adaptability to meet changing needs. Together, they can help an organization be more responsive to change and more successful.
Enterprise architect's role in an Agile environment
In an Agile environment, the role of enterprise architects is pivotal as it provides strategic direction to development teams. Without this intentional architecture, emergent design alone cannot handle the complexity of large-scale system development.
Using Hopex, companies can manage comprehensive enterprise architecture disciplines within one repository and connect business architecture, solution architecture, IT & technology architecture, portfolio management, and GRC.
This single source of truth helps organizations break down silos, avoid rework, and ensure the Agile development team’s outputs are immediately viable and successful.


