
Bizzdesign Unify: An AI-native platform for faster, better transformation decisions.
ArchiMate® 3.0 – Grouping and Junctions

In our previous blog, we outlined some of the most important changes in relationships in ArchiMate® 3.0. But there is more. In this article, we discuss updates related to the Grouping and Junction concepts in the ArchiMate modeling language. These improvements significantly enhance the expressive power of enterprise architecture models.
Groupings in ArchiMate 3.0
By popular demand, the option to use relationships to or from groupings has been added to ArchiMate, which greatly enhances the practical value of this element.
Grouping is no longer classified as a special kind of relationship: it is now a (composite) element. Composition or aggregation relationships from a grouping to an element or relationship are used to model that these concepts are part of the grouping (nesting is often used as an alternative notation for this).
As usual, composition means that the concept may only be part of one group (e.g. the wheels of your car are only on one car at the same time), while aggregation means that the concept can be part of multiple groups.
Other relationships from or to a grouping provide a shorthand notation to show that the relationship applies to all the member elements of the grouping, provided that the relationship is valid.
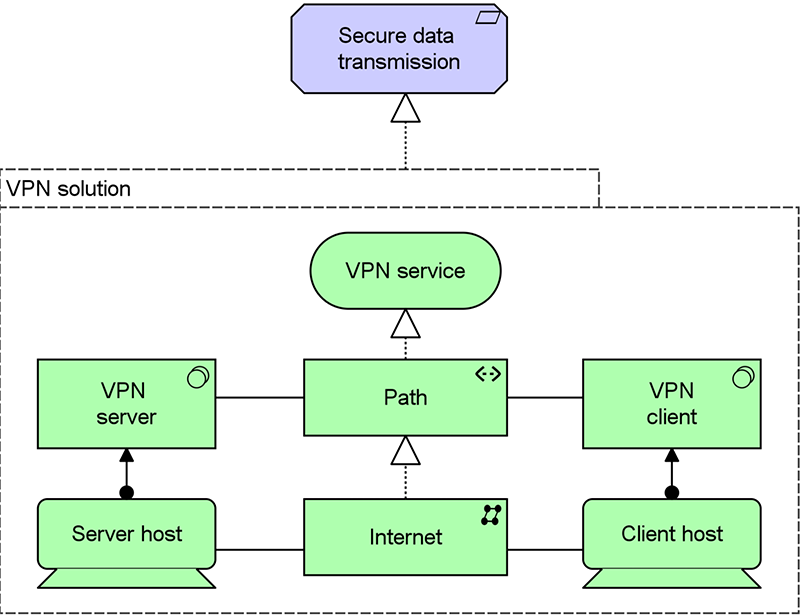
In this way, grouping can be used to model Architecture and Solution Building Blocks as described in TOGAF. As an example, Figure 1 shows a VPN solution as a grouping of technology layer elements, together realizing a requirement of secure data transmission.
Junctions in ArchiMate 3.0
There are also some changes in the use of junctions in ArchiMate 3.0.
Like groupings, junctions are no longer classified as relationships, but as a separate category of ‘relationship connectors’.
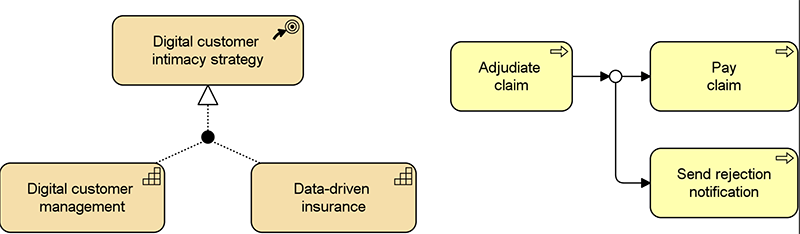
Junctions can now be used to split or join any type of relationship (except composition, aggregation and specialization), whereas in previous versions of the standard junctions could only be used with triggering and flow. Figure 2 (left) shows an example of the use of a junction to model that the two capabilities together realize the digital customer intimacy strategy.
Without the junction, the model would express that each of the capabilities on its own could realize the strategy, which you can use to express that the two capabilities provide alternative realizations.
In addition to the general junction (with AND junction as the default interpretation), a separate OR junction has been added.
Previous vs New Versions
- In previous versions of the standard, junctions could only be used with triggering and flow.
- Now, their use is expanded to many other relationship types.
Example (Figure 2, left): a junction can model that two capabilities together realize the digital customer intimacy strategy.
- Without the junction → the model would express that each capability alone could realize the strategy.
- With the junction → the model shows that both capabilities are needed.
A typical use of the OR junction is to model a choice in a process flow, as shown in Figure 2 (right), but again, an OR junction can also be used in conjunction with other types of relationships.
AND and OR Junctions
- The AND junction is the default interpretation.
- A separate OR junction has been added in ArchiMate 3.0.
These new possibilities of relationships in ArchiMate together provide an important improvement of its expressive power. This will help architects to model their designs even more precisely and concisely.
Why These Changes Matter
These new possibilities of relationships in ArchiMate 3.0 represent a major improvement in the language’s expressive power.
- Architects can now model their designs with greater precision.
- The use of groupings and junctions provides concise, flexible, and practical modeling options.
As a result, enterprise architects will find it easier to design and communicate their architectures in a way that aligns with real-world complexity.
Related Articles


