
Bizzdesign Unify: An AI-native platform for faster, better transformation decisions.
Enterprise Architecture for AI-Ready Data: Authority, Governance, and Enterprise-Scale Intelligence
Your step-by-step framework for governing enterprise semantics and authority to scale AI with control
Many enterprises have moved beyond AI experimentation. Pilots have launched, use cases are defined, funding is approved, and the expectation is scale.
Yet scaling remains uneven. Deloitte’s State of AI in the Enterprise 2026 report shows that only about 26% of organizations have moved 40% or more of their AI initiatives into production. At the same time, a majority expect to reach that level within the next three to six months.
The ambition is clear. What's often missing is the execution infrastructure that makes scale possible.
When AI moves beyond a contained pilot, it depends on context drawn from multiple systems and domains. It must understand which application record is authoritative, which process definition is current, and which data classification governs use. Where those representations conflict or lack ownership, AI reasoning becomes inconsistent. Outputs vary, recommendations are harder to defend, and decisions are difficult to trace to a trusted source.
This is a structural problem.
AI performs reliably when it connects to enterprise data that’s mastered, defined, and governed. Clear ownership, stable definitions, and shared meaning across domains give AI a consistent foundation for reasoning. Enterprise architecture plays a central role here: It defines what core concepts mean, how they relate, and which representations are authoritative.
As adoption expands across business and transformation teams, this foundation becomes more important. AI can help surface dependencies, answer questions in natural language, and make enterprise intelligence more accessible to non-specialists. That acceleration only works when both people and systems are drawing from the same governed source of truth.
Enterprise-scale AI depends on structurally authoritative and semantically consistent enterprise data. This guide explains how enterprise architecture establishes that foundation, and how the right structures make AI outputs defensible, traceable, and usable by the cross-functional teams driving transformation.
Why AI Struggles to Scale Without Governed Data
Enterprise architecture defines which data and relationships the enterprise can rely on, who maintains them, and how systems, including AI, are allowed to use them. As AI adoption expands beyond data science teams to transformation leads, compliance officers, business architects, and executives, the need for governed data access becomes enterprise wide. If enterprise architecture doesn't expose that governed intelligence across functions, AI remains siloed, and so do the decisions it informs.
Data must be both technically accurate and structurally governed to be AI-ready. Technical accuracy — completeness, correctness, timeliness — is table stakes. But structural integrity is what determines whether AI can reason reliably at enterprise scale: authority (which system governs), semantic consistency (what concepts mean), and governance (how data can be used). These are enterprise architecture disciplines; not data platform features. Without them, even technically flawless data produces inconsistent AI outputs because the foundation beneath it is unstable.
Three structural conditions determine whether AI scales with control or amplifies fragmentation:
- Authority and system of record
Enterprise architecture must designate which system is authoritative for each concept. Without that designation, AI defaults to whichever dataset is most accessible, not most accurate.
This becomes visible when AI supports enterprise-wide initiatives that require consistent understanding of what an application is, who owns it, whether it is active, and how it connects to other systems.
An “application” may exist across multiple systems: an operational inventory, a strategic architecture repository, a procurement record, a security register, or a configuration database. Each may be internally accurate, but each reflects a different purpose and update cycle.
If those systems provide different answers, which one should AI trust?
AI does not reconcile discrepancies through institutional memory or conversation like we do. It resolves them based on structured inputs and access rules. Enterprise architecture establishesthose rules by defining systems of record.
- Definition stability and semantic drift
Authority determines which system governs. Definition stability determines what the concept actually means.
Consider the term “critical application.” In one domain it may refer to revenue generation. In another, regulatory exposure. In a third, operational uptime requirements. Each definition is valid in context. But unless those contexts are explicitly modelled, the term carries multiple meanings across the enterprise.
When AI is used to assess operational risk or support IT decisions, it depends on consistent interpretation of those terms. If “critical” isn’t formally defined and governed within an enterprise ontology maintained in the EA repository, AI will apply the meaning present in whichever dataset it queries.
At scale, this produces divergence. Two teams ask similar questions and receive different answers because definitions shifted across domains.
- Embedded constraints and runtime governance
Industry research shows that enterprises are increasingly using AI to inform and support decisions that are key to business. According to McKinsey’s State of AI in 2025 report, organizations report applying AI in areas such as IT operations, knowledge management, corporate finance, and customer experience.
When AI systems are expected to participate in decision-influencing areas such as the above, they can’t simply access “all available data.” Whether a dataset should be included in an analysis depends on structural attributes such as:
- Lifecycle state: Is the process, application, or record current, deprecated, or under review?
- Approval status: Has it been validated and formally approved, or is it still draft?
- Ownership: Is there a clearly accountable owner responsible for its accuracy?
- Classification level: Does sensitivity or regulatory classification restrict its use?
- Purpose limitation: Was the data collected for a specific use that constrains how it can be applied?
For example, if an AI assistant is asked to recommend applications for decommissioning, it should automatically exclude any flagged as “under regulatory review” or “pending approval”, not rely on manual filtering after results are generated.
If these attributes aren't modeled in the enterprise architecture repository as queryable metadata, controls are applied after the fact through review and remediation. That inevitably slows scale and introduces rework.
When constraints are embedded into the data model itself, AI inherits policy boundaries automatically and governance shifts from post-execution auditing to runtime enforcement.
At enterprise scale, the difference determines whether AI expands safely or amplifies governance risk.
Enterprise architecture, when it governs data with authority and semantic consistency, determines whether AI scales with control or scales inconsistency. If there’s no clear system of record, no governed definition of core concepts, and no embedded constraints on what AI is allowed to use, AI won’t resolve the ambiguity; it will operationalize it.
What Changes When AI Moves to Enterprise Scale
Governance risk becomes operational the moment AI outputs influence decision-making. When teams rely on AI recommendations for portfolio rationalization, compliance monitoring, or process optimization, inconsistencies in enterprise data stop being reporting nuisances and start shaping outcomes.
At enterprise scale, these architectural conditions must move from principle to operational proof:
- A clearly designated system of record for each core enterprise concept.
- Stable, governed definitions that are version-controlled and consistent across domains.
- Access and usage constraints enforced directly within the data model at runtime.
The outcome depends on whether AI is restricted to approved data sources or allowed to use any available data.
This matters even more in regulated environments. Frameworks such as the EU AI Act require organizations deploying high-risk AI systems to demonstrate traceability, data governance, and accountability over how data is used. Regulators expect demonstrable controls, technical documentation, auditability, and evidence that governance is enforced in practice. That means governance must be implemented in systems and data structures, not only described in policy.
The Five Pillars of AI-Ready Enterprise Architecture
If governed enterprise data determines whether AI scales successfully, the next question is: What must enterprise architecture provide to AI to operate reliably?
The Five Pillars of AI-Ready Enterprise Architecture are defined as the capabilities that keep enterprise meaning stable and AI usage controlled as adoption scales.

Pillar 1. Authoritative data mastering and system-of-record clarity
Earlier, we established that AI can’t arbitrate between competing representations of the same enterprise concept. That requires clearly designated systems of record.
This goes beyond traditional master data management. It means:
- Each core concept such as application, process, capability, data domain or control has a designated authoritative source.
- Ownership and update responsibility are formally assigned.
- Downstream systems reference mastered entities rather than redefining them locally.
Without this discipline, AI reasoning reflects whichever dataset is most accessible. With it, AI reasoning reflects enterprise intent.
Pillar 2. Semantic consistency across domains
Authority alone is insufficient if meaning drifts. An AI-ready data architecture stabilizes definitions across the enterprise by:
- Explicitly modelling concepts rather than relying on interpretation.
- Version-controlling definitions and maintaining traceability of change.
- Making relationships between concepts machine-readable.
This semantic layer is what allows AI systems to interpret terms like “critical application,” “regulated process,” or “approved control” consistently across the business. It also enables cross-functional collaboration grounded in shared definitions.
Pillar 3. Integrated processing across structured and unstructured data
Most enterprises don’t train models from scratch. They combine existing large language models (LLMs) with enterprise data through techniques such as retrieval-augmented generation (RAG).
That introduces architectural requirements:
- Support for structured, semi-structured, and unstructured data.
- Scalable storage across hybrid or multi-cloud environments.
- Pipelines that handle both batch and real-time data ingestion.
Use cases such as customer service assistants, fraud detection, personalization, and operational copilots depend on timely signals. This requires low-latency integration and reliable consistency, not periodic reporting cycles.
The objective is governed, contextual access to relevant data at any time it’s needed.
Pillar 4. Embedded governance and runtime enforcement
As AI increases the volume and speed of data usage, governance shifts from oversight to infrastructure.
AI systems select, combine, and act on enterprise data. Policy therefore must be represented in the structures AI interacts with.
In practice, this requires:
- Lifecycle state embedded in enterprise objects so obsolete or draft records are excluded.
- Approval and validation status linked to eligibility for automated reasoning.
- Explicit ownership tied to enterprise entities to enable traceability when outputs influence decisions.
- Classification and purpose limitations enforced at query time, particularly for regulated or sensitive data.
If these attributes are absent, enforcement happens after outputs are generated. That introduces friction and rework.
When governance is structurally embedded in the data architecture, AI operates within defined policy boundaries by design. That alignment between policy, data, and execution enables scale with control.
Pillar 5. Operationalization and deployment discipline
Enterprise data evolves. Systems change, ownership shifts, classifications are refined, and integrations are introduced.
If AI systems aren’t deployed with discipline, they gradually detach from the architecture they depend on.
Operationalization is about ensuring alignment over time, and that requires:
- Versioned data and ontology states. AI must be traceable to the exact definitions and structures that were active when outputs were generated.
- Continuous validation against authoritative sources. As systems of record evolve, retrieval and reasoning layers must be revalidated to prevent silent divergence.
- Controlled rollout and rollback capability. Changes to data pipelines, ontologies, or access rules should be introduced incrementally, with monitoring that detects behavioral shifts early.
Without this discipline, scale creates instability. With it, AI remains aligned with enterprise intent.
How Enterprise Architecture Achieves Semantic Consistency
Moving from analyzing data to enabling AI reasoning depends on semantic discipline within enterprise architecture. Authority and definition stability, identified earlier as prerequisites for scale, don't emerge by default. Achieving them requires semantic discipline across the enterprise.
A single source of truth doesn’t mean a single database, but rather that each core enterprise concept is governed consistently, regardless of where it is consumed. It's also a collaboration enabler. When everyone speaks the same language, transformation moves faster.
For AI to reason reliably across domains, four conditions must hold:
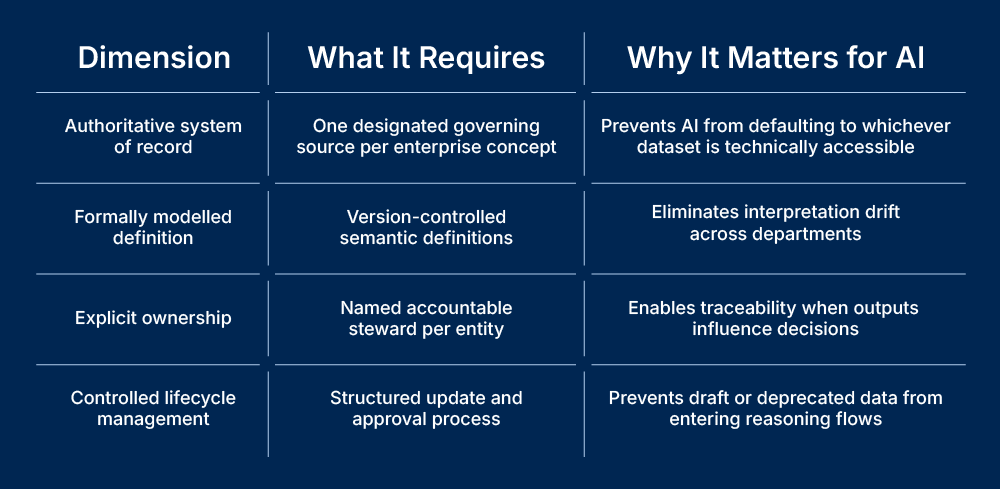
Master data represents core enterprise entities such as applications, capabilities, processes, customers, or controls. Reference data provides classification context such as criticality level, regulatory category, or lifecycle stage.
If master entities are duplicated or reference values diverge across systems, semantic fragmentation follows. AI then reasons over locally valid but globally inconsistent representations.
Enterprise ontology addresses this by defining typed objects and explicit relationships across domains. When that ontology is accessible across teams, and not just to architects, it becomes a shared language for transformation.Instead of inferring meaning from documents or loosely structured artifacts, AI interacts with governed models that encode enterprise intent directly.
This structural clarity is what allows AI reasoning to remain consistent as usage expands further and further.

How MCP Connects AI to Governed Enterprise Architecture
What semantic discipline gives you is structure. What AI needs next is a controlled way to interact with that structure at runtime. Enterprise architecture models, even when governed, remain internal artifacts unless there’s a consistent interface that AI systems can query and reason over directly.
Model Context Protocol (MCP) provides that interface. It defines a standardized layer that lets AI applications access enterprise models as structured, typed data rather than as detached text or siloed records. Instead of inferring context from fragmented sources, MCP connects to a governed architecture repository and exposes:
- Typed object definitions and attributes
- Relationships and dependencies across domains
- Lifecycle states and governance metadata
- Access constraints enforced at runtime

Exposing architecture data this way, MCP turns a static model into active “AI-ready intelligence.”.That means thatwhen an AI assistant queries enterprise data, it issues a structured query against a single, governed model. The resulting outputs reflect enterprise semantics, traceable ownership, and embedded governance rather than opportunistic interpretation.
In mature environments, this interface enables controlled participation in workflows. AI can reason about what is permitted, what is approved, and what is current. The difference is clear: AI moves from scraping context to reasoning within enterprise intent.
MCP also connects AI to governed data in a way that makes enterprise intelligence accessible across the organization. Business strategists, compliance officers, architects, and IT leaders can query the same governed model through AI assistants. Decisions align more quickly because teams operate from a shared understanding of enterprise structure and meaning.
This shift transforms architecture from documentation into operational intelligence. Instead of waiting for reports or mediated interpretations, teams act directly on shared, governed insight. That’s how EA teams gain the capacity to focus on strategic initiatives, accelerating transformation while maintaining control.
A Practical Roadmap for AI-Ready Enterprise Data
The architecture described above develops through cross-functional commitment, executive sponsorship, and sustained investment in governance practices and enabling infrastructure. Teams that succeed treat it as enterprise change, supported by clear ownership and operating routines, rather than a one-off data effort.
The roadmap below outlines a practical path from authority designation to enterprise-wide operational intelligence, with each phase building on the last. Timelines vary based on governance maturity, the number of systems involved, and the scope of AI use cases.
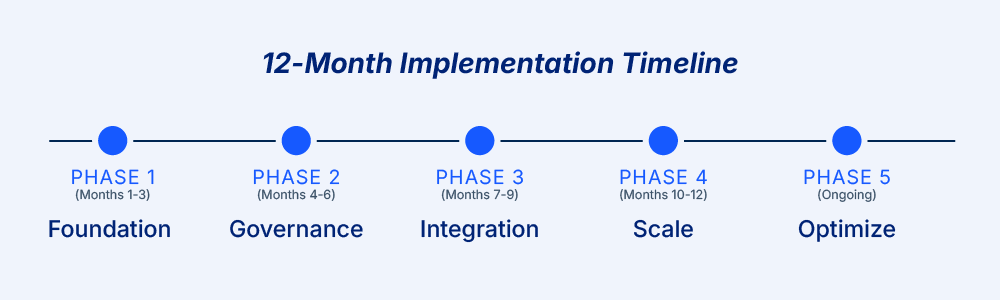
Phase 1: Building the Foundation (Months 1–3)
Identify the 10 enterprise concepts most critical to priority AI use cases (often applications, processes, capabilities, data domains, controls). Then:
- Designate an authoritative system of record for each concept so AI retrieves governed context from a defined source.
- Assign named data stewards with operational accountability for accuracy, change approval, and conflict resolution.
- Baseline semantic consistency by identifying where definitions drift across systems and teams.
Phase 2: Embedding Governance and Semantic Consistency (Months 4–6)
With authority established, the next phase makes governance enforceable in the model and metadata AI relies on:
- Model core concepts in an enterprise ontology as machine-readable definitions that support consistent interpretation.
- Version and track definition changes so shifts in meaning remain traceable over time.
- Embed lifecycle state, ownership, and approval status so constraints can be applied consistently at query time (e.g., excluding “items under regulatory review” or “pending evaluation”).
- Add monitoring to detect drift and conflicts in authoritative sources.
Phase 3: Enabling AI Access via Controlled Interfaces (Months 7–9)
This phase connects AI applications to your governed architecture through a controlled interface layer. Model Context Protocol (MCP) is one open standard used to connect AI applications to external systems and tools.
- Configure AI applications to query your enterprise architecture repository as their authoritative source for context. This means AI issues structured queries against typed objects, explicit relationships, and governed metadata, rather than scraping documents or stitching together fragmented APIs.
- Implement traceability so outputs can be linked back to sources used, constraints applied, and the ontology/version active at the time.
Pilot 2–3 AI use cases with production data. Validate that queries return consistent results across teams, that governance constraints are enforced automatically, and that lineage is complete and auditable.

Phase 4: Scaling to Enterprise-Wide AI Adoption (Months 10–12)
With pilots validated, this phase expands governance and access across the enterprise. The discipline established in earlier phases now scales to support multiple use cases and cross-functional teams.
- Extend authoritative coverage. Expand systems of record beyond the initial concepts to additional applications, processes, and data domains.
- Onboard new AI use cases using the same governance model. Apply the same authority, semantic, and constraint discipline from Phase 3.
- Implement continuous validation. As the EA repository evolves, revalidate AI queries and reasoning patterns to prevent silent divergence.
- Formalize ontology change management. When definitions shift or new constraints are introduced, test and redeploy dependent AI experiences in a controlled manner.
- Enable governed access for cross-functional teams. Ensure business architects, compliance officers, and transformation leaders can query the same authoritative intelligence that powers AI.
Phase 5: Optimizing and Maintaining Alignment (Ongoing)
AI-ready architecture requires sustained operational discipline as systems, definitions, and ownership evolve.
- Monitor semantic drift proactively. When teams begin interpreting terms differently or local definitions diverge from authoritative sources, resolve conflicts before they propagate into AI reasoning.
- Refine governance rules based on usage patterns. As AI use cases mature, you'll identify constraints that are too restrictive (blocking valid queries) or too permissive (allowing policy violations). Adjust runtime rules iteratively.
- Expand integration responsibly. Introduce new data sources and AI applications using established governance and validation practices.
- Conduct regular stewardship reviews. Confirm that ownership and accountability remain active and operational.
- Measure and report on AI output quality and trust metrics. Track consistency across teams, governance violation rates, lineage completeness, and user confidence in AI-generated recommendations.
How to Evaluate Enterprise Architecture Platforms for AI
The roadmap outlined above depends on a technology foundation capable of supporting formal ontology, runtime governance patterns, and controlled AI access. Building AI-ready architecture requires clarity across three platform areas: the enterprise architecture repository, the AI integration layer, and governance capabilities aligned with the architecture model.
When evaluating platforms, focus on whether they support structured reasoning, enforceable constraints, and traceable outputs.
Core Platform Requirements
Enterprise Architecture Repository
Your EA repository must support formal ontology modeling with version control that goes beyond diagrams or documentation to provide machine-readable definitions that AI can query. It should enable typed object definitions and explicit relationships, so AI understands not just that "Application A" exists, but that it depends on "Data Domain B," is governed by "Control C," and supports "Capability D."
Lifecycle state, ownership, and approval status must be queryable attributes so when an AI assistant asks, "Which applications are approved for cloud migration?" the repository should return structured results based on governed metadata.
Integration across strategic portfolio management, business architecture, and application portfolio management ensures governed intelligence flows across transformation disciplines.
AI Integration Layer
The integration layer exposes governed architecture as structured, typed data for AI queries. Model Context Protocol (MCP) is an open standard used to connect AI applications to external systems, though other structured interface approaches can achieve the same outcome.
The core requirement is direct, structured access. AI systems should query the repository using defined schemas and relationships rather than scraping exports or relying on static data extracts.
Access policies and governance constraints should be enforced at query time, and queries should be logged with sufficient metadata to support traceability and audit needs.
Data Governance Capabilities
Governance capabilities ensure master and reference data remain aligned with the enterprise architecture model.
Platforms should support:
- Classification and purpose limitation
- Drift detection across authoritative sources
- Conflict resolution workflows
- Documentation practices aligned with regulatory expectations (for high-risk AI systems under frameworks such as the EU AI Act)
Governance rules defined in the platform should be reflected in the architecture model and inherited by AI applications through structured access patterns.

Vendor Evaluation Criteria
When evaluating vendors, prioritize six dimensions:
- Metamodel depth: Can the platform represent multi-domain relationships and dependencies beyond flat hierarchies?
- Semantic governance: Are definitions version-controlled and formally structured, or limited to free-text documentation?
- AI-native interfaces: Can AI applications query the model directly via structured interfaces like MCP, or does integration require custom workarounds?
- Runtime enforcement: Are governance constraints enforceable through the model and access layer?
- Ecosystem integration: Does it connect to your existing EA, strategic portfolio management, business architecture, and collaboration tools, or does it operate in isolation?
- Proven at scale: Has the platform supported complex, multi-domain environments where governance and dependency depth materially affect outcomes?
Common Pitfalls and How to Avoid Them
Selecting the right EA repository, AI integration layer, and governance platform to enable AI-ready architecture is necessary, but implementation discipline determines success.
Five patterns consistently derail otherwise well-designed initiatives. Recognizing them early makes the difference between controlled scale and expensive rework.
- Treating data as an IT-only concern
Enterprise data (and the enterprise architecture that defines its authority and meaning) underpins business transformation. It requires cross-functional ownership. Business architects define what core concepts mean. Compliance establishes constraints. Data stewards maintain accuracy. Enterprise architects enforce structural consistency.
When architecture ownership sits solely within IT, definitions drift from business intent and AI reasoning becomes disconnected from enterprise reality.
Fix: Establish a cross-functional governance council with named representatives from IT, business architecture, compliance, and transformation leadership. Make data stewardship an operational role with defined accountabilityand measurable responsibilities.
- Assuming UX improvements alone will solve collaboration gaps
A well-designed collaboration tool connected to fragmented or ungoverned data still produces misalignment, only faster and at greater scale. The issue is structural, not interface-based.
What matters is whether the tool connects to authoritative, semantically governed architecture.
Fix: Prioritize governed data architecture first, then layer accessible interfaces on top. Collaboration tools should query the same EA repository that powers AI, ensuring cross-functional teams access the same authoritative intelligence.
- Deploying AI without validating data authority and semantic consistency
When AI scales without designated systems of record, governed definitions, and structural constraints, outputs diverge. Trust erodes gradually. Exceptions increase. Conflicts surface during portfolio reviews, compliance checks, or operational transitions.
Retroactive correction is far more expensive than upfront alignment.
Fix: Make data architecture readiness a prerequisite for AI production deployment. No use case should move beyond pilot until authoritative sources are designated, definitions are governed, constraints are enforceable, and traceability mechanisms are in place.
- Implementing governance as policy documents instead of embedded constraints
Policy documents describe intent, while embedded constraints enforce it.
When governance exists only in SharePoint or policy repositories, enforcement depends on manual review. That doesn't scale in environments where AI evaluates data continuously.
Lifecycle state, approval status, classification level, and ownership must be structural attributes in the enterprise model; not notes reviewed after outputs are generated.
Fix: Encode governance constraints directly in the enterprise architecture data model so AI inherits policy boundaries automatically at query time.
- Skipping lineage tracking and traceability
Regulatory compliance and audit requirements demand demonstrable evidence of how AI reached a conclusion. If you can't trace an AI output back to its authoritative source, the governance rules applied, and the version of the ontology in effect, you can't defend the reasoning, especially in regulated industries subject to frameworks like the EU AI Act.
Fix: Implement lineage tracking from day one. Every AI query should generate an audit trail showing which data was accessed, which constraints were applied, and which version of the ontology governed the reasoning.

Conclusion: From Ambition to Execution
The gap between AI ambition and AI execution is structural. Scale depends on authoritative systems of record, stable definitions, and enforceable governance embedded in enterprise architecture.
Without authority and semantic consistency, AI scales inconsistency. With them, AI scales shared meaning and defensible outcomes.
Organizations that succeed treat this as enterprise change. They establish cross-functional governance, embed policy in structured models, and make architecture intelligence accessible to the teams shaping decisions.
When business strategists, compliance officers, and transformation leaders can query the same governed architecture that powers AI, alignment improves and late-stage conflict decreases.
That shift from architecture as documentation to architecture as operational intelligence defines the next phase of enterprise AI readiness.
Bizzdesign is investing in both: The governed data architecture that makes AI trustworthy, and the accessible interfaces that make that architecture available to every team shaping transformation.

FAQs
AI-ready data architecture is defined as the structural foundation that enables AI to scale reliably across an enterprise. It includes authoritative systems of record, semantically governed definitions, embedded governance constraints, and controlled interfaces that allow AI to query enterprise data while inheriting policy boundaries automatically.
AI pilots fail to scale when they rely on local datasets and informal definitions that don’t hold across domains. At enterprise scale, AI needs authoritative systems of record, stable semantic definitions, and enforceable usage constraints; without them, outputs diverge across teams, exceptions multiply, and trust erodes before production rollout can expand.
An authoritative system of record is defined as the governing source for a specific enterprise concept that other systems reference rather than redefine. In enterprise architecture for AI, it establishes which representation of an application, process, capability, data domain, control, risk, policy, asset, or ownership structure should be treated as the approved basis for reasoning when multiple systems contain overlapping versions.
Enterprise ontology improves AI reasoning by making enterprise meaning explicit, structured, and machine-readable. It defines core objects (such as applications, capabilities, controls), their attributes, and their relationships so AI can interpret terms consistently, traverse dependencies reliably, and produce outputs that reflect enterprise intent rather than local interpretation.
Model Context Protocol (MCP) works by providing a structured interface between AI applications and enterprise systems through MCP servers that expose approved data and tools. Instead of scraping documents or relying on static exports, an AI assistant translates a user request into structured calls against governed models and services, returning results grounded in defined object types, explicit relationships, governance metadata, and lifecycle state, with access controlled by policy.
It also enables non-expert teams to access governed enterprise intelligence through natural language querying. Business strategists, compliance officers, and transformation leaders can explore architecture models without needing deep technical expertise, while the underlying structure ensures consistency, traceability, and policy enforcement.
When AI systems influence workflows, compliance monitoring, or operational decisions, governance can’t rely on policy documents alone. Lifecycle state, approval status, ownership, classification, and purpose limitations must be represented as structured attributes in the data architecture. If they aren’t, enforcement happens after outputs are generated, slowing scale and increasing risk.
An enterprise architecture platform for AI should support formal, machine-readable modeling of enterprise concepts and relationships, with version-controlled definitions that remain traceable over time. Governance attributes such as lifecycle state, ownership, and approval status must be embedded as queryable metadata so constraints can be enforced at runtime. It should also expose structured access for AI applications and maintain traceability that links outputs back to the authoritative sources, applied rules, and definition state in effect.
Frameworks like the EU AI Act require organizations deploying high-risk AI systems to demonstrate traceability, data governance, and accountability. Governed data architecture provides the technical foundation for compliance by embedding lifecycle state, ownership, approval status, and classification constraints directly in the data model, enabling end-to-end lineage tracking from source to AI output.
Enterprise architecture gives organizations the visibility they need to understand how AI connects to existing systems, processes, data flows, and risks. A shared architectural view helps teams see dependencies upfront, avoid overlaps, and prevent the fragmentation that causes pilots to stall. Enterprise architecture also helps ensure AI initiatives align with strategic priorities and can be governed consistently across the business, turning isolated experiments into scalable enterprise capabilities. By providing the structural context for decision-making, EA enables AI investments to deliver measurable value and supports the shift from experimentation to scaling what works.




Make Enterprise Data Usable for AI at Scale
Connect AI to governed architecture models with clear ownership, lifecycle state, and semantics.