
Bizzdesign Unify: An AI-native platform for faster, better transformation decisions.
Designing the AI-Native Enterprise: Embedding Intelligence into Your Operating Model
Most enterprises operating today were designed long before AI could participate in work. Their operating models assume that people interpret context and make decisions, while systems execute predefined steps. Intelligence sits in documents, policies, and institutional memory. That architecture still underpins how work gets done.
What has changed is the expectation placed on AI. It’s now positioned to operate within workflows and influence outcomes. As pressure to adopt AI has intensified, driven by employees seeking productivity gains, markets and investors watching progress, and customers encountering AI-enabled experiences elsewhere, many organizations have responded by moving quickly. Different motivations, same outcome: AI layered onto operating models never designed to support it.
The limits of that approach are starting to show. According to PwC’s 2026 Global CEO Survey, only one in eight CEOs (12%) say AI has delivered both cost and revenue benefits. The same research shows that organizations with strong AI foundations including responsible AI frameworks and technology environments designed for enterprise-wide integration are three times more likely to report meaningful financial returns.
The difference isn’t how much AI an organization deploys, but how clearly the enterprise is structured and governed as AI operates. Organizations that see sustained results maintain a defined, authoritative view of how their enterprise works. That structure, often maintained through enterprise architecture (EA), gives AI the context it needs to operate reliably across domains. Without it, scale amplifies inconsistency rather than value.
This is where the term AI-native enterprise enters the conversation, and where it’s often misunderstood.
What Does “AI-native” Mean?
AI-native is frequently used to describe organizations that adopt AI early or deploy it broadly. We mean something more specific: An operating model designed on the assumption that AI will participate in work alongside people, applications, and data.
In an AI-native operating model, intelligence is embedded into workflows rather than layered at the edges. AI agents are treated as architectural components with clearly defined roles and operating limits. Decisions about how much autonomy they have, what data they can use, and where human review is required are set deliberately, rather than being added after systems are already in production.
The difference becomes clearer as organizations move beyond early pilots, where success is often driven by tightly scoped environments and controlled usage. AI can appear effective even when layered onto existing systems, but strain begins to surface as adoption widens and the technology interacts with more of the enterprise landscape.
- First, data reliability degrades. AI is asked to reason across multiple sources that describe the same enterprise concepts in different ways. Processes exist in architecture tools, diagrams, spreadsheets, and document repositories — often duplicated, inconsistently defined, and unevenly maintained. At small scale, humans reconcile these differences implicitly. At larger scale, AI can’t. It either produces conflicting outputs or fabricates answers by arbitrarily selecting between sources.
- Second, performance and maintainability decline over time. An AI capability that works for a single team often becomes unstable when exposed to enterprise-wide usage and continuously changing data. Without a defined architecture for how AI accesses data, how instructions evolve, and how quality is maintained, accuracy erodes. What looked promising in controlled environments becomes unreliable in production.
- Third, governance is introduced too late. In AI-added environments, privacy, compliance, and usage constraints are frequently enforced outside the flow of execution. Data is passed to AI first and assessed afterward. That approach doesn’t hold when AI outputs influence decisions or modify enterprise data. Once trust erodes through inconsistent results, unclear provenance, or compliance gaps, adoption slows or stops entirely.

These outcomes reflect operating models that were never built for intelligence to participate directly in work. When AI usage expands without rethinking those foundations, limitations surface that no model upgrade can fix.
The most immediate constraint is the data AI relies on to reason.
Why Data Quality is Critical for AI to Scale
When AI begins operating across domains, inconsistencies in enterprise data quickly become visible.
At this point, the relevant questions are about structure, authority, and intent.
To scale AI successfully, pause early and examine data through a different lens. Not “do we have enough data,” but:
- Which data is AI permitted to access and rely on securely?
- How consistently are core enterprise concepts defined?
- Who owns those definitions, and how are they kept current?
- Which representations are authoritative, and which are contextual?
AI doesn’t interpret ambiguity the way people do. When enterprise concepts such as processes, applications, or ownership exist in multiple forms across tools and documents, humans reconcile gaps. AI, as stated earlier, can’t. It will either surface contradictions or make a choice on the user’s behalf (often without visibility into how that choice was made.)
AI-native operating models address this by making data authority explicit. They designate trusted systems of record for specific concepts and ensure those sources are governed and maintained.
Enterprise architecture plays a central role here. It provides a structured representation of applications, processes, ownership, and dependencies, allowing AI to reason over approved models rather than fragmented documentation. When that structure is current, AI can produce enterprise-aware outputs grounded in how the organization operates.
Why Enterprise AI Performance Degrades Without Architectural Foundations
Once data authority is established, many organizations expect AI performance to stabilize. In practice, this is where a second constraint appears: Maintaining quality over time.
AI systems are often deployed as fixed capabilities, but enterprises aren't static. Processes change, applications are updated or retired, ownership shifts, policies evolve, and responsibilities move between teams. As these changes accumulate, outputs begin reflecting outdated assumptions rather than current reality.
This degradation is rarely dramatic. It shows up as subtle inconsistencies or answers that are technically plausible but no longer aligned. Because the decline is incremental, it can go unnoticed until trust erodes.
AI-native organizations design for maintainability from the outset. They treat AI behavior as something that must evolve alongside the enterprise. Access rules are reviewed as systems change. Instructions are versioned. Outputs are validated against current architectural models rather than static documentation.
When something changes, the impact is visible, allowing teams to adjust before quality degrades further.
Embedding Governance Where AI Operates
In many organizations, governance is introduced after AI is already in use. Rules around privacy, compliance, and acceptable use are documented centrally, while AI operates at the edge of workflows. That separation holds as long as AI outputs are advisory. It breaks down as soon as AI recommendations shape decisions or modify enterprise data.
AI-native operating models address this by embedding governance directly into execution by:
- Making autonomy explicit. Instead of leaving boundaries to user judgment, AI-native organizations design autonomy levels into workflows; defining what runs automatically, what requires validation, and what remains analysis-only.
- Tying governance to data state. Rather than allowing AI to access any available data and validating outputs afterward, governance rules operate at runtime — approval status, ownership, and lifecycle state determine what AI can reason over.
- Calibrating human oversight to risk. Instead of uniform approval requirements that either slow all work or create blanket risk, oversight is introduced at points where decisions carry material consequence.
The table below illustrates how these shifts operate in practice:
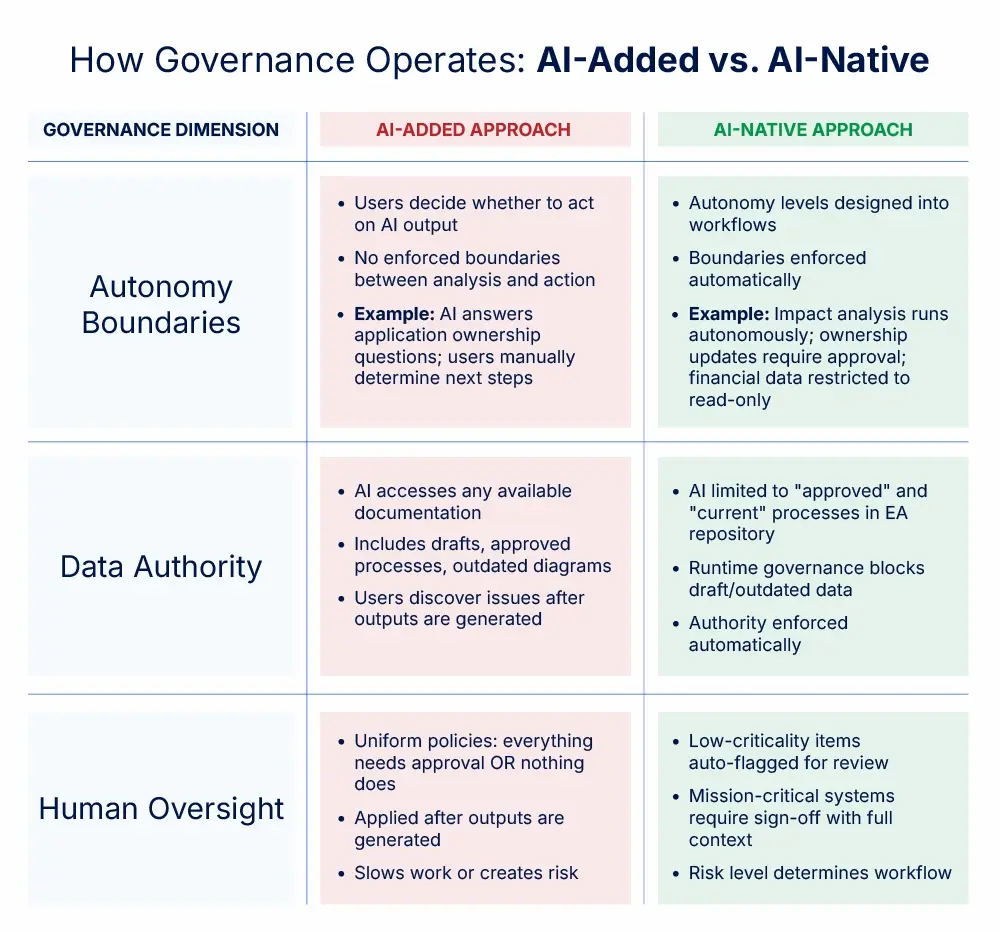
Governance that lives outside the workflow is easy to document and hard to enforce. Governance that lives inside the workflow scales with AI. This means governance and enterprise context must be present where decisions are formed, not surfaced weeks later during execution.
AI Agents as Architectural Components
When governance and enterprise context are embedded directly into execution, AI can take on a different role. It no longer operates as an assistant responding to prompts at the edge of the workflow. It becomes a participant within it.
Gartner estimates that by the end of 2026, up to 40% of enterprise applications will include task-specific AI agents, up from less than 5% in 2025. As these agents become embedded into applications, they shift from assisting users to executing defined tasks within workflows.
An AI agent in this context is a bounded actor in enterprise work that can reason over structured context, coordinate actions across systems, and operate within defined constraints.
Consider application rationalization. In an AI-added environment, a user asks which applications are redundant. The tool scans documentation and produces a list. A person then validates dependencies, checks ownership, and evaluates risk before acting.
In an AI-native environment, an agent reasons directly over the enterprise architecture repository. It identifies overlap based on capability models, confirms that the data is current and approved, surfaces dependencies and ownership, flags compliance considerations, and routes higher-risk actions for review while allowing lower-risk steps to proceed.
In an AI-native environment, an agent reasons directly over the enterprise architecture repository. It identifies overlap based on capability models, confirms that the data is current and approved, surfaces dependencies and ownership, flags compliance considerations, and routes higher-risk actions for review while allowing lower-risk steps to proceed.
The difference is coordinated action grounded in governed enterprise context.
Enabling this requires controlled, programmatic access to that context. Mechanisms such as Model Context Protocol (MCP) expose enterprise architecture as a machine-readable system of record. Agents can interpret lifecycle state, trace dependencies, and operate within established boundaries by design rather than assumption.
As architectural foundations mature, agents can expand in scope without sacrificing explainability or control. Multiple agents may operate across domains, each constrained by the same structural and governance rules. Workflows become visible, versioned artifacts within the enterprise architecture rather than informal sequences of steps.

How to Evolve Toward an AI-Native Operating Model
Most enterprises weren't built with AI as a participant from the start; that's simply the reality for any organization that predates this shift. Existing systems and processes were designed for valid reasons and still carry value. The challenge is evolving how they work as intelligence becomes a participant in execution.
Start with the problem AI needs to solve. Examine which enterprise concepts require governance and maintenance. Identify where human oversight remains essential and where automation can proceed safely. Build the foundations of authoritative data, governance embedded into execution, agents with clear scope before expanding usage.
This evolution is rarely linear. Hybrid states are common, with some workflows remaining human-led while others incorporate AI incrementally. What matters is architectural intent: clear boundaries for where AI acts, what context it relies on, and how accountability scales with autonomy. With that foundation in place, organizations can expand AI’s role in enterprise work while maintaining control today and as conditions, regulations, and technologies continue to evolve.
FAQs
An AI-native enterprise is an organization whose operating model is designed on the assumption that AI will participate in work alongside people, applications, and data. Intelligence is embedded into workflows rather than added as an external layer, with clear rules for autonomy, governance, and accountability.
AI-added means bolting AI capabilities onto existing systems without redesigning how work flows or how decisions are governed. AI-native means designing workflows, data authority, and governance with AI as a participant from the start, treating AI agents as architectural components with defined responsibilities and boundaries rather than productivity tools layered on top of existing processes.
AI agents rely on enterprise architecture for structured, authoritative context. In other words, the enterprise ontology that defines how the business works. It defines core concepts like applications, processes, ownership, dependencies, and lifecycle state, and establishes which data is approved and current.
Without that structure, agents operate on fragmented information and can’t reliably assess impact or enforce governance. With it, they can reason over trusted models, trace dependencies, and act within defined constraints across the enterprise.
AI doesn't interpret ambiguity the way people do. When enterprise concepts like processes, applications, or ownership exist in multiple forms across tools and documents, humans resolve differences implicitly while AI can't. It either surfaces contradictions or makes arbitrary choices without visibility into how those decisions were made.
Data authority establishes which systems are trusted sources for specific enterprise concepts, ensuring AI reasons over consistent, governed data rather than conflicting or outdated information. Without data authority, AI performance degrades as usage scales and enterprise conditions change.
Becoming AI-native doesn't require replacing existing systems or starting from scratch. Most enterprises already rely on complex portfolios of applications and platforms that continue to serve important business functions. What changes in an AI-native approach is how those systems are used, governed, and connected when AI participates in work.
Related Articles




Enterprise-Ready AI, Built Into the Enterprise Transformation Suit
Keep enterprise architecture data accurate and consistent, without manual clean-up.